パケット転送のマルチコア処理
マルチコアCPU搭載機種は複数のCPUによってパケット転送を並列処理します。ここでは並列処理の仕組みと制限について説明します。
基本的な仕組み
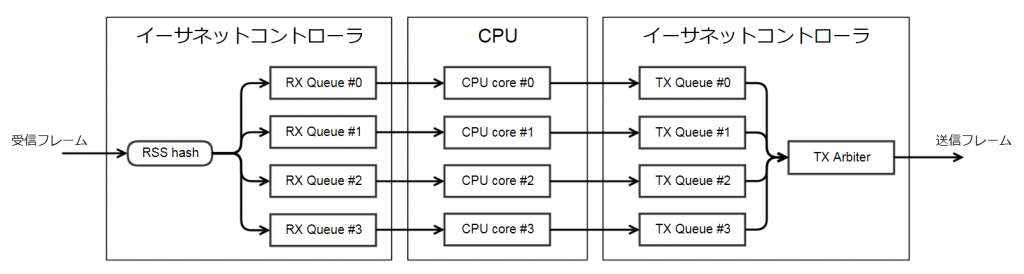
パケット転送処理は、図のように受信キューから送信キューまでの処理を一つのパスとして並列化されます。
並列処理の単位はIPフロー(送信元と送信先の組み合わせ)です。受信パケットのIPフローからハッシュ値を計算し、その値ごとに受信キューを振り分け、受信から送信までのパスが並列化されます。
このため、並列処理の適用可否は、送受信の方向(受信インタフェース)によります。
ハッシュ値が同じIPフローは同じパスで処理するため、通信傾向によってはIPフロー(ハッシュ値)が偏りCPUリソースを活かしきれない場合がありますが、フレーム単位で複数のパスに振り分けると僅かな処理時間差によって送信順序が入れ替わり、TCPの再送機構等により通信速度が低下する可能性があります。
このフレームの整列処理を単純化するためにも、ひとつのIPフローのフレームは同一の処理パスを通るように設計されています。
IPフローの単位
TCPパケットの場合は、IPヘッダの送信元アドレス、送信元ポート番号、送信先アドレス、および送信先ポート番号からハッシュ値を計算します。このため送受信アドレスおよびポート番号が全て同じ組み合わせの場合に同一フローとみなされます。
VPNパケットは対向装置毎にIPフローがひとつになるため、ひとつの対向からの受信トラフィックは上記の基本的な仕組みでは並列化されません。後述のVPNパケット受信後の処理によって並列化されます。
CPUの割当について
- SEIL/X4
- 搭載する4個のCPUコアによる並列処理を行います。
- SEIL/x86 Ayame エンタープライズエディション/トライアルエディション
- 仮想マシンに割り当てられた8個までのCPUによる並列処理を行います。
- SEIL/x86 Ayame スタンダードエディション(ver.3.00以降)
- 仮想マシンに割り当てられた2個までのCPUによる並列処理を行います。
- SEILアプライアンスシリーズ CA10
- 10GbEポート(4/10G, 5/10G)への入力は、搭載する8個のCPUコアによる並列処理を行います。
イーサネット・IPの受信処理
イーサネットでIPパケットを転送する場合に、イーサネットコントローラが持つReceive-Side Scaling(RSS)機能によって、マルチコアCPUを活かしたパケット転送の並列処理が可能です。
イーサネットインタフェース(ge[])またはVLANインタフェース(vlan[])の受信フレームのペイロードの先頭がIPヘッダである場合に、IPフローに基づく並列化の対象になります。これらのインタフェースがブリッジインタフェース(bridge[])に所属する場合も同様です(ルーティング、ブリッジング共に働きます)。
イーサネットフレーム(またはVLANフレーム)を受信すると、ペイロード内のIPフローからハッシュ値を計算し、値ごとに受信キューに振り分けます。
PPPoEの受信処理
イーサネットインタフェースのRSS機能はPPPoEフレームに対応していないため、PPPoE(pppoe[])インタフェースは常に1つの受信キューで受信します。
その後PPPoEフレームから取り出したIPパケットを並列処理するために、CPUがPPPoE処理部でペイロード内のIPフローからハッシュ値を計算することで、IP処理部以降を並列処理します。
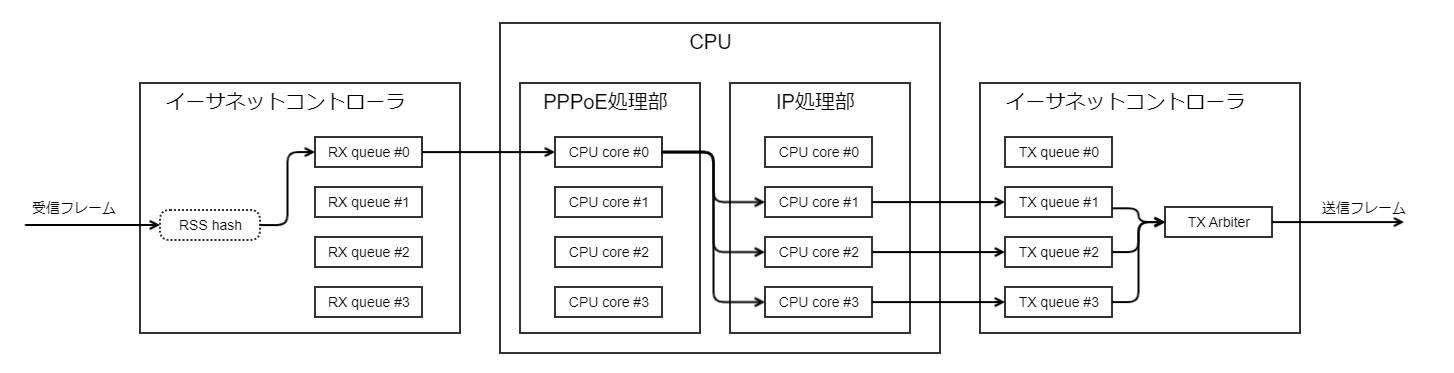
PPPoEを処理するCPUの負荷を下げることでより効率的なCPU負荷分散を行うために、IP処理部はPPPoE処理CPUを避けて振り分けます。
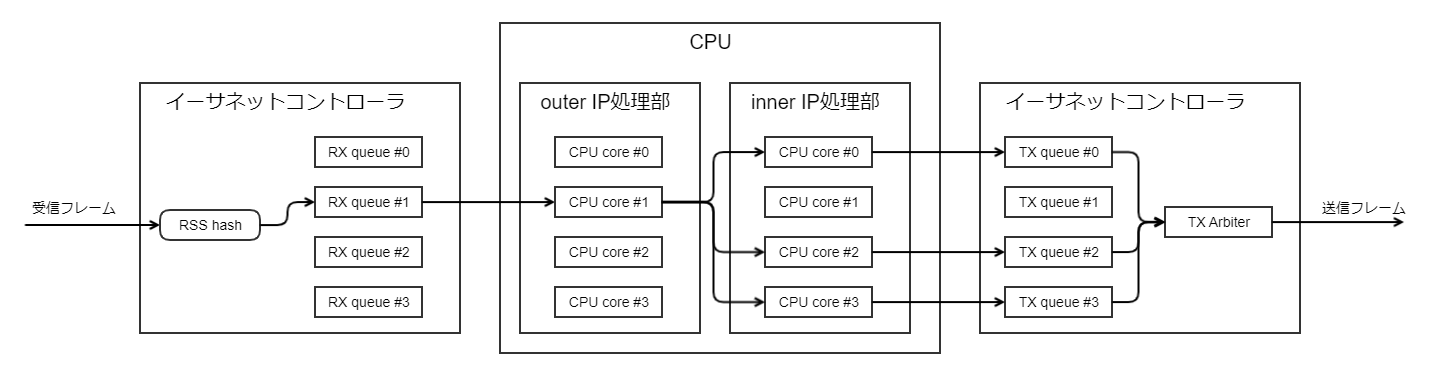
IPトンネルの受信処理
イーサネットのRSS機能はペイロード先頭のIPフローによる振り分けを行うため、IP-IP(tunnel[])やIPsec(ipsec[])インタフェースは、VPN対向ごとに1つの受信キューで受信します。
その後VPN内の通信を並列処理するために、CPUがouter IP処理部でペイロード内のIPフローから発出を計算し、inner IP処理部以降を並列処理します。
IPトンネル over PPPoEの受信処理
PPPoEサービス上でVPN接続を行う場合は、前述の動作に基づき、イーサネット部で並列化されず、PPPoE処理部でVPNパケットごとに並列化され、さらにVPN内のIPフローごとに並列化されます。
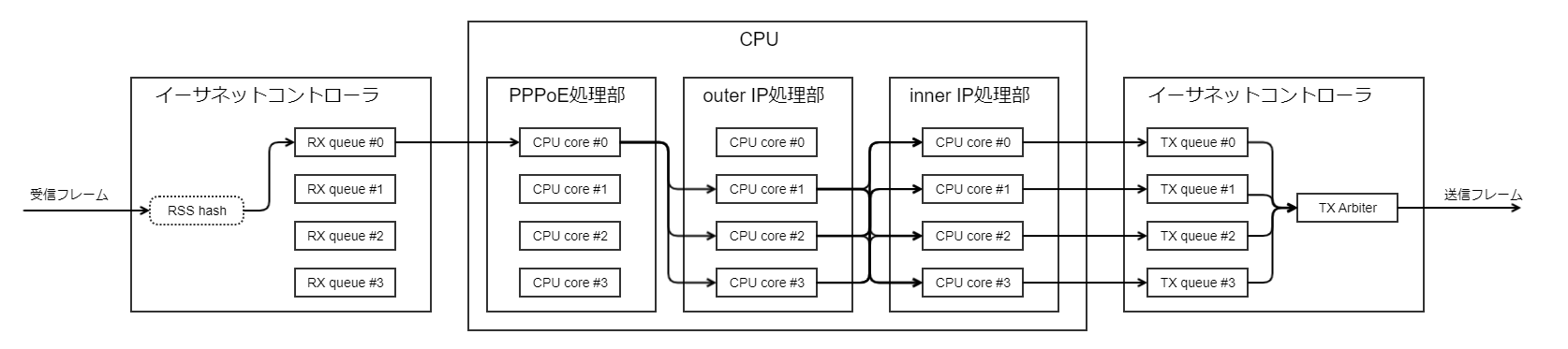
PPPoE処理部ではPPPoEペイロード内のIPフロー、つまりカプセル化されたVPNパケットのouter IPフローから計算したハッシュ値による振り分けが行われます。
さらにouter IP処理部ではVPNトンネル内のIPフロー、つまりinner IPフローから計算したハッシュ値による振り分けが行われます。
制限等
本装置自身が送信元となるパケットは、受信処理を経ないため並列処理されません。
- NTPやDHCP、Iperf、IKEなど、自身が通信を終端する機能の送信処理
- DNS中継やアプリケーションゲートウェイなどの代理通信機能(プロキシ系機能)の送信処理
次のVPNトラフィックは inner IPフローが並列処理されません(VPN内の通信が並列処理されません)。outer IPフローによってVPN対向毎に並列処理されます。
- L2TPv3の受信処理
- ポリシーベースIPsecの受信処理
- PPPACの受信処理
バージョンによる差異・変更
- PPPoE受信処理の並列化
- IPトンネル受信処理の並列化
これらの並列化対応は多くの用途で転送性能の向上が確認されていますが、通信傾向によっては転送性能が低下する可能性があります。
例えばIPトンネルが小数(目安として3本以上8本以下)であり、かつ、各トンネル内のinner IPフローが小数(目安として6フロー以下)であると、並列化処理の負荷が効果を上回る可能性があります。
option.tunnels-cpu-distribution : disable